Anomaliedetektion vs. Segmentierung
Folge 3
Autorin: Hanna Nennewitz
Anomaliedetektion vs. Segmentierung
Folge 3
Autorin: Hanna Nennewitz

Nachdem ich mir in der letzten Folge die Vor- und Nachteile von regelbasierten Systemen und ML-basierten Systemen angeschaut habe, steige ich heute noch tiefer in die Funktionsweise ML-basierter Systeme ein. Dabei lege ich meinen Fokus auf unterschiedliche Wege der Fehlererkennung durch Anomaliedetektion (=unüberwachtes Lernen) und Segmentierung (=überwachtes Lernen).
In dieser Folge sollen sowohl ihre Funktionsweisen als auch Vor- und Nachteile deutlich werden. Um mehr über das Thema zu erfahren, habe ich mit Dr. Adrien Deliège gesprochen. Adrien arbeitet als Lead Machine Learning Engineer bei Maddox AI und wirkt sowohl bei der Produktentwicklung als auch bei der konkreten Umsetzung von Kunden-Use Cases mit. Zudem koordiniert er Forschungsprojekte, die in Kooperation mit Maddox AI umgesetzt werden.
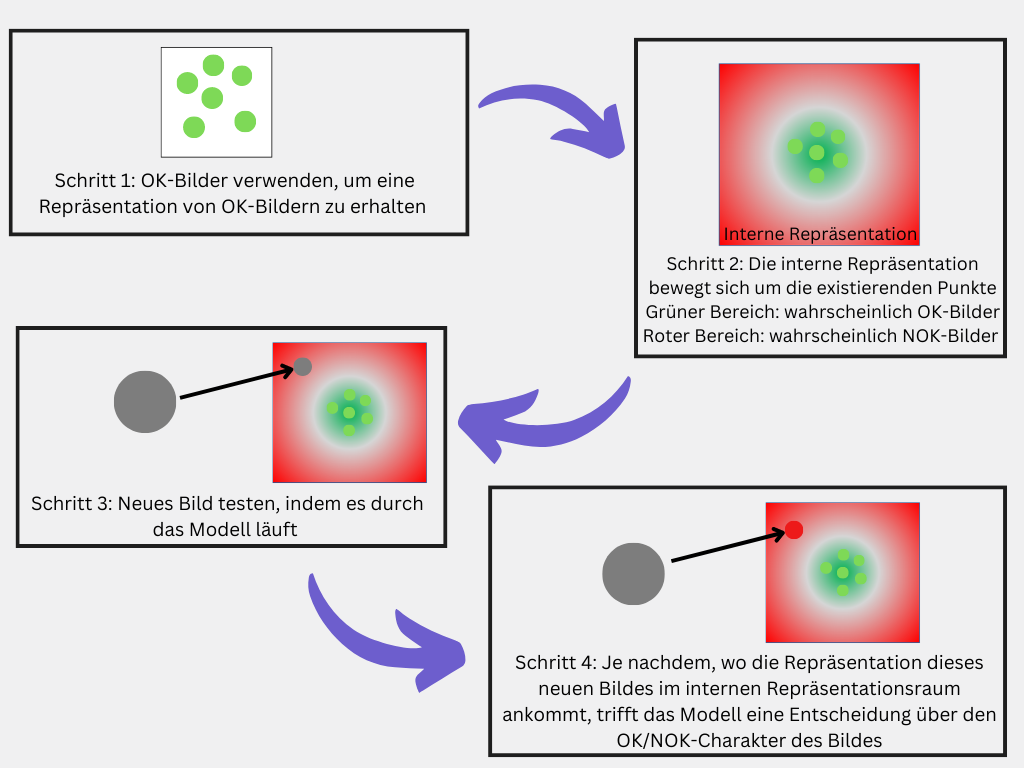
Modelle, welche auf Anomaliedetektion basieren, identifizieren alles, was auf irgendeine Art und Weise anders aussieht als das Standardprodukt. Das heißt, es wird nicht genau kategorisiert, welche Art von Fehler erkannt wird, sondern alles, was vom Aussehen des Standardproduktes abweicht, wird aussortiert. Trainiert wird das System üblicherweise nur mit OK-Bildern. Adrien erklärt: “Das System erstellt eine interne Repräsentation dessen, wie das Standardprodukt aussieht, indem ihm OK-Produkte gezeigt werden. Wenn es dann einen neues Produkt analysiert, berechnet es, wie sehr dieses von der internen Repräsentation abweicht. Weicht es zu stark ab, wird es als „anomal“ eingestuft und aussortiert.“ Das macht den Implementierungsprozess recht einfach, da nur Bilder von OK-Teilen benötigt werden, um das Modell auf den spezifischen Anwendungsfall zu trainieren.
Nachdem ich mir in der letzten Folge die Vor- und Nachteile von regelbasierten Systemen und ML-basierten Systemen angeschaut habe, steige ich heute noch tiefer in die Funktionsweise ML-basierter Systeme ein. Dabei lege ich meinen Fokus auf unterschiedliche Wege der Fehlererkennung durch Anomaliedetektion (=unüberwachtes Lernen) und Segmentierung (=überwachtes Lernen). In dieser Folge sollen sowohl ihre Funktionsweisen als auch Vor- und Nachteile deutlich werden. Um mehr über das Thema zu erfahren, habe ich mit Dr. Adrien Deliège gesprochen. Adrien arbeitet als Lead Machine Learning Engineer bei Maddox AI und wirkt sowohl bei der Produktentwicklung als auch bei der konkreten Umsetzung von Kunden-Use Cases mit. Zudem koordiniert er Forschungsprojekte, die in Kooperation mit Maddox AI umgesetzt werden.
Modelle, welche auf Anomaliedetektion basieren, identifizieren alles, was auf irgendeine Art und Weise anders aussieht als das Standardprodukt. Das heißt, es wird nicht genau kategorisiert, welche Art von Fehler erkannt wird, sondern alles, was vom Aussehen des Standardproduktes abweicht, wird aussortiert. Trainiert wird das System üblicherweise nur mit OK-Bildern. Adrien erklärt: “Das System erstellt eine interne Repräsentation dessen, wie das Standardprodukt aussieht, indem ihm OK-Produkte gezeigt werden. Wenn es dann einen neues Produkt analysiert, berechnet es, wie sehr dieses von der internen Repräsentation abweicht. Weicht es zu stark ab, wird es als „anomal“ eingestuft und aussortiert.“ Das macht den Implementierungsprozess recht einfach, da nur Bilder von OK-Teilen benötigt werden, um das Modell auf den spezifischen Anwendungsfall zu trainieren.
“Im Vergleich zur Anomaliedetektion bietet Segmentierung tiefere Einblicke in die Produktion, da Segmentierung auch eine Analyse der verschiedenen Fehlertypen ermöglicht.”
“Oberflächeninspektion mit Hilfe von Segmentierung ist in den meisten unserer Fälle viel effizienter als die Anomalieerkennung”
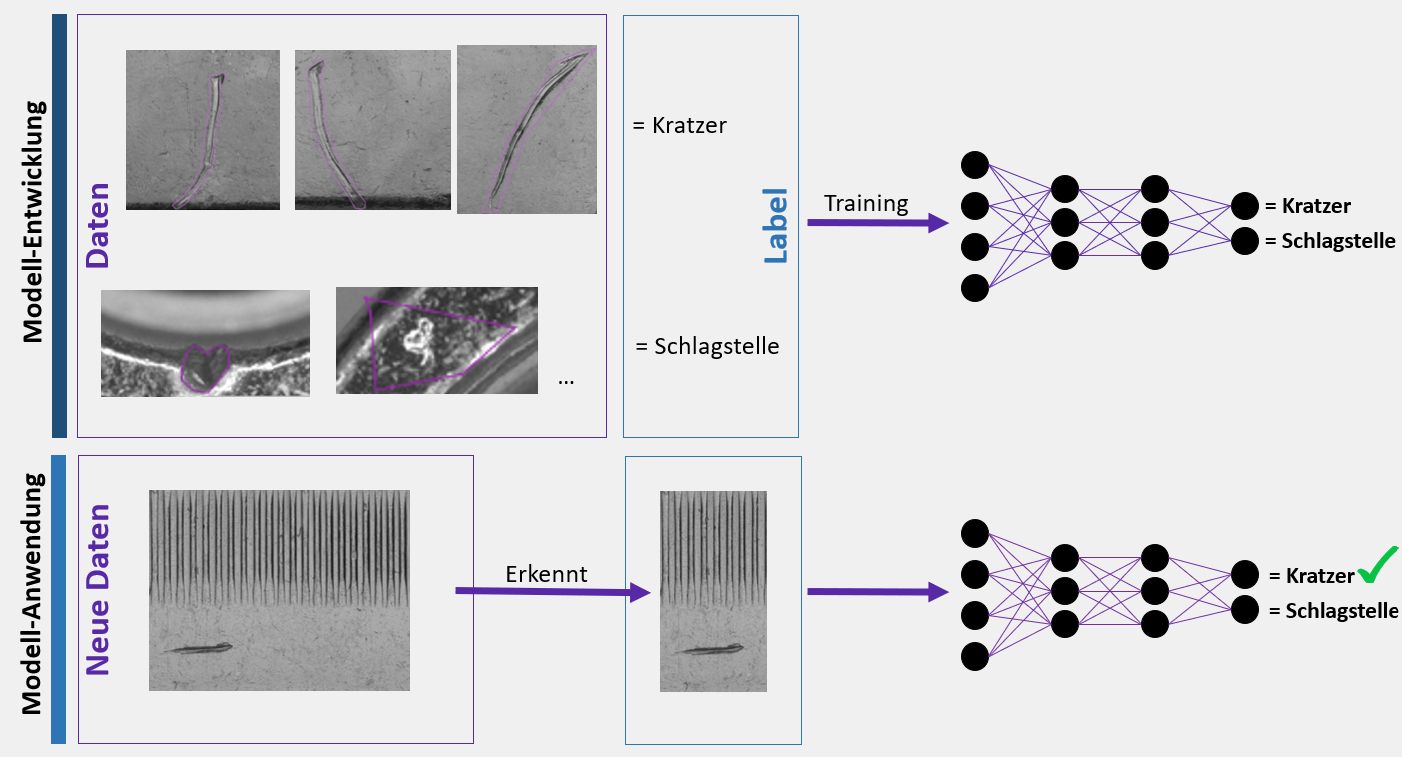
Bei Segmentierungsmodellen haben Kunden ebenfalls den Vorteil, dass genau festgelegt werden kann, was als Fehler gelten soll und was nicht. Das kann beispielsweise besonders wichtig bei der Oberflächeninspektion sein. Adrien erklärt dazu: “Oberflächeninspektion mit Hilfe von Segmentierung ist in den meisten unserer Fälle viel effizienter als die Anomalieerkennung. Bei der Anomalieerkennung kann man sich nicht ganz sicher sein, was aussortiert wird. Manche Bilder sind sehr komplex und es ist gar nicht so einfach, Defekte zu erkennen. Die Anomaliedetektion kann hier sehr, sehr empfindlich sein und zu viele anomale Muster erkennen, da die Variabilität in den Mustern zu groß ist. Das führt dazu, dass einige Muster für die Anomaliedetektion als anomal erscheinen, obwohl sie es gar nicht sind. ” Für ein Segmentierungsmodell kann man hingegen genau festlegen, auf was geachtet werden soll. Das verringert das Risiko für Pseudoauschuss deutlich. Adrian erzählt: „Wir haben z.B. gerade diesen Fall: Einer unserer Kunden ändert regelmäßig die Definition eines Fehlertyps. Wir können jedes Mal entsprechend neu annotieren und die Modelle neu trainieren. Bei der Anomalieerkennung hat man weder diese Kontrolle noch die Flexibilität, das zu tun.“
Dieses genaue Festlegen von Fehlertypen und worauf geachtet werden soll, bietet ebenfalls den Vorteil, dass Segmentierungsmodelle auch sehr kleine Fehler erkennen können. Im Training können die Modelle genau auf diese kleinen kleinen Fehler trainiert werden, in dem man sie durch entsprechende Annotationen darauf fokussiert. Bei Anomaliedetektion sähe das anders aus, erklärt mir Adrien: “Für Anomaliedetektion ist das Erkennen kleiner Fehler eher schwer, da besonders auf größeren Oberflächen die Anomalien zu klein sind, um das grundsätzliche Aussehen der Objekte stark genug zu beeinflussen.” Dieses Erkennen kleiner Fehler auf Oberflächen ist jedoch häufig wichtig in der industriellen Qualitätskontrolle: “Oft geht es darum, kleine lokalisierte Defekte auf großen Flächen zu finden. Die Anomalieerkennung ist nicht empfindlich genug, um diese gewünschten Defekte zu finden, der Segmentierungsansatz hingegen schon.”
Bei einem Anomaliedetektionsmodell kann man sich jedoch darauf verlassen, dass es auch bei neuen Defekten zuverlässig arbeitet.
Es kann aber auch Nachteile haben, die Fehlertypen genau festzulegen. Sollten neue Fehlertypen auftauchen, kann ein Segmentierungsmodell darauf auf zwei Arten reagieren: Entweder übergeht es diese einfach, weil es diese noch nie gesehen und nicht gelernt hat, dass es sich um einen Defekt handelt. Oder, wenn der neue Fehler z.B. groß genug ist, wird das Modell die Teile zwar immer noch als defekt markiert, aber die falsche Fehlerklasse vorhersagen. Bei einem Anomaliedetektionsmodell kann man sich darauf verlassen, dass es auch bei neuen Defekten zuverlässig arbeitet. Wird ein ungewöhnliches Muster erkannt, so wird es einfach aussortiert, ohne dass es eine Rolle spielt, dass es sich dabei um eine andere Art von Defekt handelt.
Ändert sich aber gewollt ein Produktmerkmal oder es gibt unterschiedliche Produkttypen, bei denen die Fehler jedoch gleich aussehen, so prüft das Segmentierungsmodell regulär weiter, während das Anomaliedetektionsmodell viele Teile fälschlicherweise als fehlerhaft aussortiert. Das liegt daran, dass das Segmentierungsmodell anhand der gelernten Fehlertypen prüft, während die Anomaliedetektion das gesamte Aussehen der Teile in Betracht zieht.
“Im Grunde lässt sich jeder Anwendungsfall durch Segmentierung abdecken, solange Beispiele für die Defekte zur Verfügung stehen.”
Außerdem wollen wir durch eine genaue Fehleranalyse dazu beizutragen, dass in der Produktion immer weniger Ausschuss entsteht.
Die bessere Kontrolle über die Fehlererkennung sowie die Möglichkeit der Fehleranalyse sind auch die Gründe dafür, warum sich das Team von Maddox AI sich dafür entschieden hat in den meisten Fällen auf Segmentierungsmodelle zu setzen. Dieses kann, bei Bedarf, aber natürlich auch mit einem Anomaliedetektionsmodell kombiniert werden. Es ist uns wichtig, dass unsere Kunden möglich genau kontrollieren können, was aussortiert wird. Außerdem wollen wir durch eine genaue Fehleranalyse dazu beizutragen, dass in der Produktion immer weniger Ausschuss entsteht. Das macht unser Kunden zufrieden und trägt zusätzlich dazu bei, dass die Produktion insgesamt ressourcenschonender wird.
Wenn Sie den Eindruck haben, dass ein Segmentierungsmodell für Ihre visuelle Qualitätskontrolle eine große Hilfe sein könnte und Sie sich wünschen, einen genauen Einblick in das Auftreten von Fehlern in Ihrer Produktionslinie zu erhalten, melden Sie sich gerne bei uns. Das Maddox AI-System kann Ihnen genau das ermöglichen.
Nachdem es sich in den letzten Folgen nun viel um den Algorithmus der KI gedreht hat, wende ich mich in der nächsten Folge der Rolle der Datenbasis zu und erkläre, wie sich die Performanz eines KI-Modells steigern lässt.
Wie kann ich die Leistung meines KI-Modells verbessern?
Folge 4
