Anomaly Detection vs. Segmentation
Episode 3
Author: Hanna Nennewitz
Anomaly Detection vs. Segmentation
Episode 3
Author: Hanna Nennewitz

After looking at the advantages and disadvantages of rule-based systems and ML-based systems in the last episode, today I'm going deeper into how ML-based systems work. I will focus on different ways of error detection by anomaly detection (=unsupervised learning) and segmentation (=supervised learning).
In this episode, their modes of operation as well as advantages and disadvantages will become clear. To learn more about the topic, I spoke with Dr. Adrien Deliège. Adrien works as a Lead Machine Learning Engineer at Maddox AI and contributes to both product development and the actual implementation of customer use cases. He also coordinates research projects implemented in collaboration with Maddox AI.
After looking at the advantages and disadvantages of rule-based systems and ML-based systems in the last episode, today I’m going deeper into how ML-based systems work. I will focus on different ways of error detection by anomaly detection (=unsupervised learning) and segmentation (=supervised learning). In this episode, their modes of operation as well as advantages and disadvantages will become clear. To learn more about the topic, I spoke with Dr. Adrien Deliège. Adrien works as a Lead Machine Learning Engineer at Maddox AI and contributes to both product development and the actual implementation of customer use cases. He also coordinates research projects implemented in collaboration with Maddox AI.
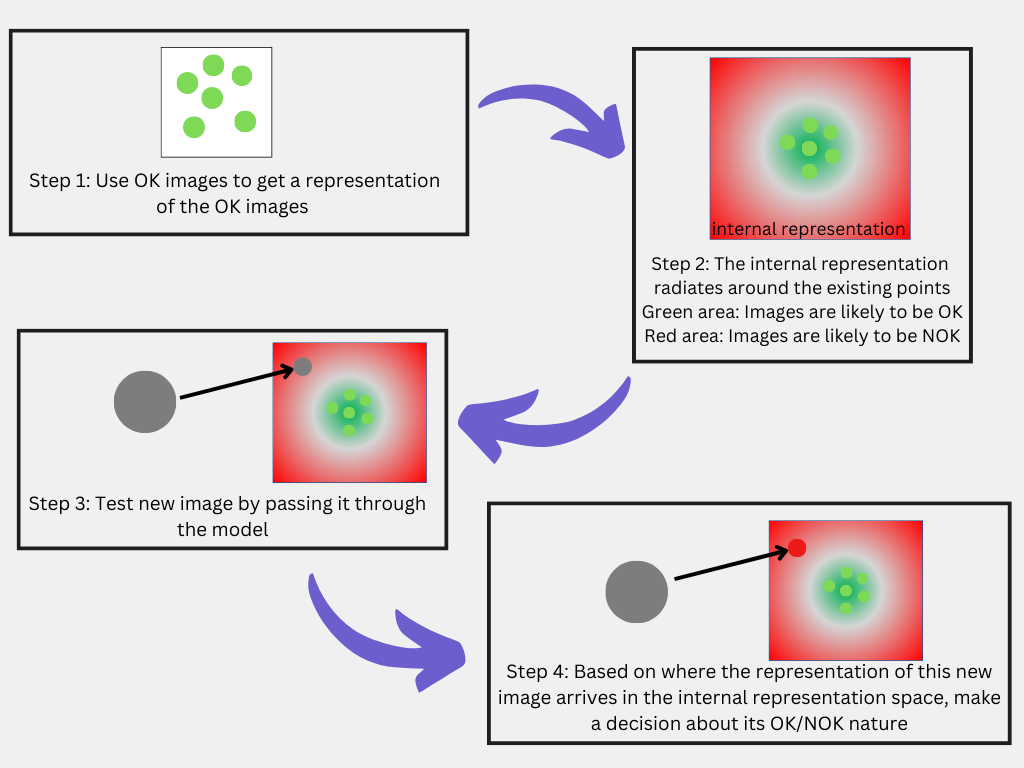
Models based on anomaly detection identify anything that looks different from the standard product. It does not categorize exactly what type of defect is detected, but anything that deviates from the appearance of the standard product is sorted out. The system is usually trained with OK images only. Adrien explains, “It builds an internal representation of what a standard product is by looking at OK products, then, when it analyzes a new item, it computes how different from that internal representation the item is. If it’s too different, it will be considered as “anomalous” and will be sorted out.” This makes the implementation process quite simple, as only images of OK parts are needed to train the model on the specific use case.
"Compared to anomaly detection, segmentation offers deeper insights into production because segmentation also allows analysis of different defect types."
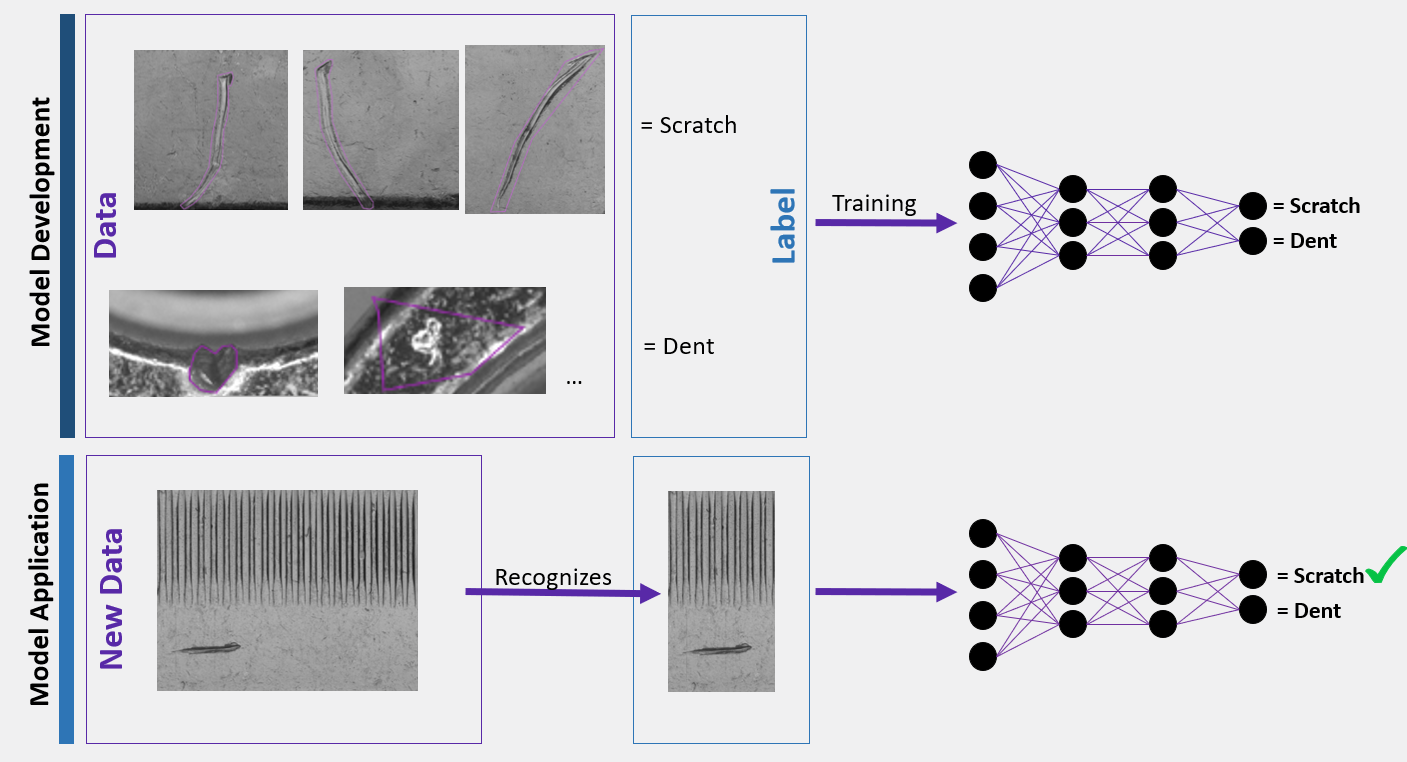
"Surface inspection using segmentation is much more efficient than anomaly detection in most of our cases."
With segmentation models, customers also have the advantage of being able to specify exactly what should and should not be considered as a defect. This can be particularly important in surface inspection, for example. Adrien explains, “Surface inspection using segmentation is much more efficient than anomaly detection in most of our cases. You don’t know what you will get with anomaly detection. Some images are very complex and not easy at all to detect defects and sometimes it’s a bit borderline. So some patterns might appear anomalous, but they are not. Anomaly detection models can be very, very sensitive and detect many, many anomalous patterns because the variability in the patterns is just too high.” For a segmentation model, on the other hand, you can specify exactly what to look for. This significantly reduces the risk for pseudo scrap. Adrian tells me, “For example, we have this case right now: one of our customers regularly changes the definition of a defect type. We can re-annotate accordingly each time and re-train the models. With anomaly detection, you don’t have that control or the flexibility to do that.”
This precise specification of error types and what to look for also offers the advantage that segmentation models can detect very small errors. In training, the models can be trained on exactly these small errors by focusing on them through right annotations. For anomaly detection, it’s a different story, Adrien tells me: “For anomaly detection, detecting small errors is rather hard, because especially on larger surfaces, the anomalies are too small to affect the basic appearance of the objects strongly enough.” However, this detection of small defects on surfaces is often important in industrial quality control: “Often it really comes down to finding small, localized defects on large surfaces. Hence, anomaly detection will not be sensitive enough to find the defects that we want whilst segmentation is.”
An anomaly detection model, however, can be relied upon to work reliably even with new defects.
However, specifying the defect types so precisely can also have its disadvantage. If new defect types emerge, a segmentation model can respond to them in one of two ways: Either it simply passes them over because it has never seen them before and has not learned that they are defects. Or, if the new defect is large enough, for example, the model will still mark the parts as defective but predict the wrong defect class. An anomaly detection model can be relied upon to work reliably even with new defects. If an unusual pattern is detected, it is simply sorted out. It does not matter that it is a different type of defect.
However, if a product feature changes intentionally, or if there are different types of products but the defects look the same, the segmentation model continues to inspect regularly, while the anomaly detection model incorrectly sorts out many parts as defective. This is because the segmentation model checks based on the learned defect types, while anomaly detection considers the overall appearance of the parts.
“Yet, basically every use case can be covered by segmentation, as long as examples of the defects of interest can be provided.”
We also want to use accurate defect analysis to help reduce scrap in production.
The better control over defect detection as well as the possibility of defect analysis are also the reasons why the Maddox AI team has decided to rely on segmentation models in most cases. However, this can, of course, be combined with an anomaly detection model if needed. It is important to us that our customers can control as precisely as possible what is sorted out. In addition, we want to contribute to less and less waste in production by means of accurate defect analysis. This makes our customers satisfied and also helps to make production more resource-efficient overall.
If you feel that a segmentation model could be of great help for your visual quality control and you wish to get an accurate insight into the occurrence of defects in your production line, feel free to contact us. The Maddox AI system can help you do just that.
Now that the last few episodes have focused a lot on the AI algorithm, in the next episode I will turn to the role of the database and explain how the performance of an AI model can be increased.
How can I improve the performance of my AI model?
Episode 4
