Wie kann ich die Leistung meines KI-Modells verbessern?
Folge 4
Autorin: Hanna Nennewitz
Wie kann ich die Leistung meines KI-Modells verbessern?
Folge 4
Autorin: Hanna Nennewitz

Ich habe mich in den letzten Folgen viel mit der Algorithmusseite von KI beschäftigt. Der Algorithmus ist jedoch nur einer von zwei Hebeln, um leistungsstarke KI-Modelle zu entwickeln. Letztlich benötige ich eine Kombination aus den besten Algorithmen und einer guten Datenbasis, um die optimale Modell-Performance zu erzielen. Das Thema Datenqualität werde ich heute genauer betrachten. Dafür mache ich ein kleines Experiment und spreche mit Alexander Böttcher über die Wichtigkeit von guten Daten für die erfolgreiche Arbeit eines KI-Modells. Bei Maddox AI ist Alexander Böttcher als ML-Engineer für die Entwicklung der Maddox AI ML-Trainings- und Deployment-Pipeline zuständig. Zusätzlich entwickelt er ML-Methoden, die es Benutzer:innen erlauben, schnell konsistente Datensätzen zu annotieren.
Alexander beginnt unser Gespräch mit einem kleinen Gedankenexperiment: Die optimalen Voraussetzungen für einen guten Kaffee erhält man zum einen durch eine gute Kaffeemaschine und zum anderen durch gute Kaffeebohnen. Letztendlich hängt jedoch der Geschmack des Kaffees hauptsächlich von der Qualität der Bohnen ab. Das heißt, wenn man schlechte Bohnen in eine perfekte Kaffeemaschine gibt, so wird man schlechten Kaffee trinken, egal wie ausgeklügelt der Prozess des Kaffeemachens in der Maschine sein mag. Alexander erklärt mir, dass es bei KI-Modellen ähnlich ist: “Auch bei KI-Modellen ist die Voraussetzung für ein perfekt funktionierendes Modell ein optimaler Algorithmus und eine optimale Datenbasis. Gebe ich jedoch inkonsistente Daten in einen optimalen Algorithmus, so wird dieser Algorithmus trotzdem nicht optimale Ergebnisse erzielen. Aus diesem Grund ist es wichtig, die Qualität der Daten, mit denen man eine KI trainiert, genauer zu untersuchen.”
Ich habe mich in den letzten Folgen viel mit der Algorithmusseite von KI beschäftigt. Der Algorithmus ist jedoch nur einer von zwei Hebeln, um leistungsstarke KI-Modelle zu entwickeln. Letztlich benötige ich eine Kombination aus den besten Algorithmen und einer guten Datenbasis, um die optimale Modell-Performance zu erzielen. Das Thema Datenqualität werde ich heute genauer betrachten. Dafür mache ich ein kleines Experiment und spreche mit Alexander Böttcher über die Wichtigkeit von guten Daten für die erfolgreiche Arbeit eines KI-Modells. Bei Maddox AI ist Alexander Böttcher als ML-Engineer für die Entwicklung der Maddox AI ML-Trainings- und Deployment-Pipeline zuständig. Zusätzlich entwickelt er ML-Methoden, die es Benutzer:innen erlauben, schnell konsistente Datensätzen zu annotieren.
Alexander beginnt unser Gespräch mit einem kleinen Gedankenexperiment: Die optimalen Voraussetzungen für einen guten Kaffee erhält man zum einen durch eine gute Kaffeemaschine und zum anderen durch gute Kaffeebohnen. Letztendlich hängt jedoch der Geschmack des Kaffees hauptsächlich von der Qualität der Bohnen ab. Das heißt, wenn man schlechte Bohnen in eine perfekte Kaffeemaschine gibt, so wird man schlechten Kaffee trinken, egal wie ausgeklügelt der Prozess des Kaffeemachens in der Maschine sein mag. Alexander erklärt mir, dass es bei KI-Modellen ähnlich ist: “Auch bei KI-Modellen ist die Voraussetzung für ein perfekt funktionierendes Modell ein optimaler Algorithmus und eine optimale Datenbasis. Gebe ich jedoch inkonsistente Daten in einen optimalen Algorithmus, so wird dieser Algorithmus trotzdem nicht optimale Ergebnisse erzielen. Aus diesem Grund ist es wichtig, die Qualität der Daten, mit denen man eine KI trainiert, genauer zu untersuchen.”
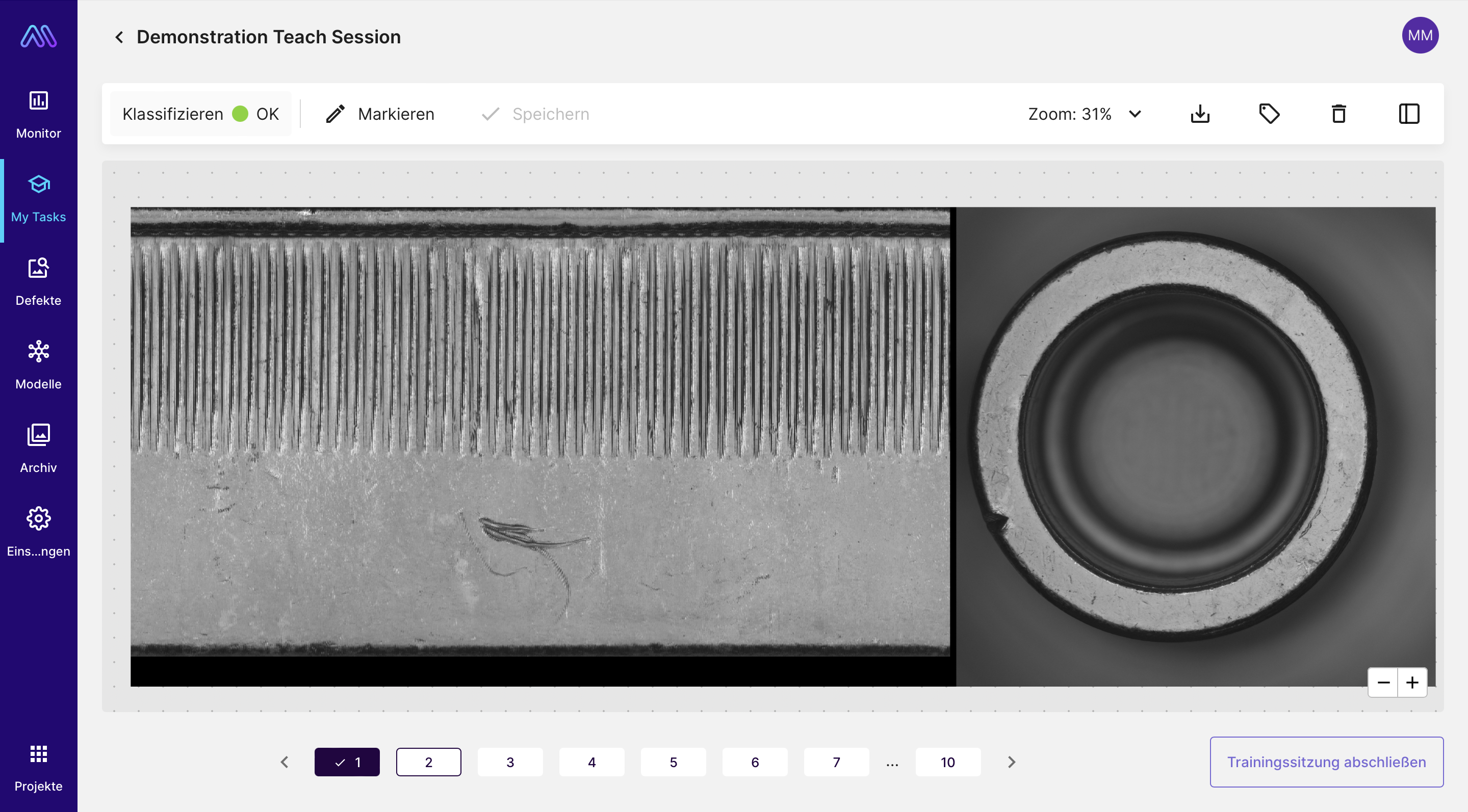
Beispielbild der zu annotierenden Teile
Auf diesen Drehteilen sollen sie mithilfe von Polygonen Defekte markieren und dokumentieren, ob es sich dabei um Kratzer oder Schlagstellen handelt. Nachdem die Annotationen erfolgt sind, trainieren wir das Maddox AI-System damit. Als das Training abgeschlossen ist, schauen wir uns die Erkennungsgenauigkeit des Modells an. Sie liegt bei 74%, was natürlich nicht besonders gut ist. Für mich stellt sich hier sofort die Frage: Woran liegt das, eigentlich funktioniert das Maddox AI-System doch sehr verlässlich? Alexander erklärt mir, dass es an der Qualität der annotierten Daten liegt: “Es ist ein Problem, wenn die Datengrundlage, mit der wir die KI trainieren, nicht einheitlich ist, weil dann die KI keine einheitlichen Daten zum Lernen hat.”
Daher schauen wir uns gemeinsam die Statistik zum Klassenrauschen in der Maddox AI Cloud Software an. Hier kann man eine grobe Übersicht zur Übereinstimmung der Annotationen der einzelnen Annotierer:innen einsehen.
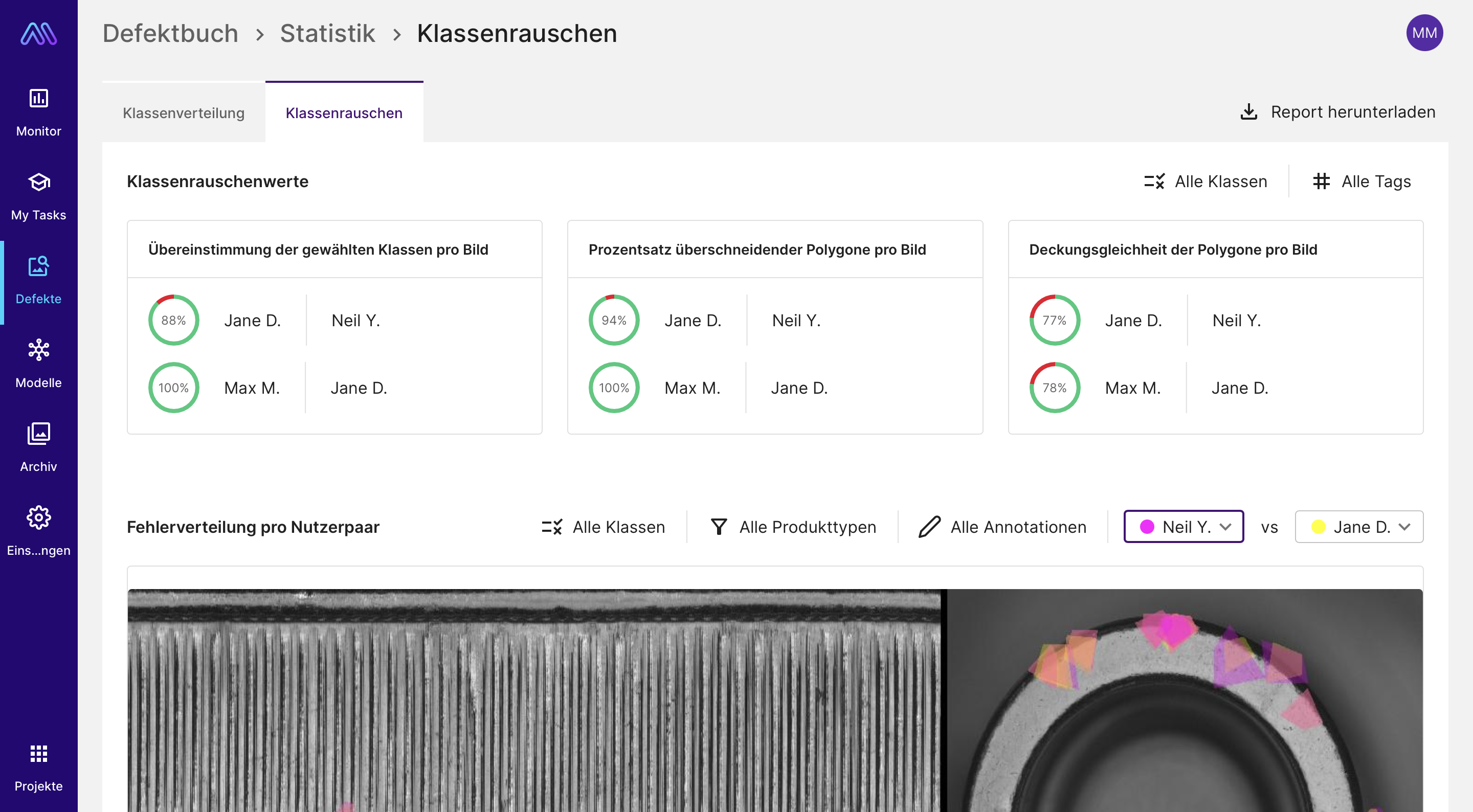
Die Statistik zum Klassenrauschen in der Maddox AI Cloud Software, hier kann man eine grobe Übersicht zur Übereinstimmung der Annotationen der einzelnen Annotierer:innen finden

Beispiel 1: Hier wurden von der ersten Person zwei Schlagstellen markiert, während die andere Person die zweite etwas kleinere Schlagstelle übersehen hat.

Beispiel 2: Hier wurde der Kratzer sehr unterschiedlich markiert. Die eine Annotation liegt sehr eng am Kratzer, während die andere sehr weit gezeichnet ist und viele freie Stellen einbezieht, die eigentlich nicht zum Kratzer gehören.

Beispiel 3: Hier wurde ein Kratzer markiert. In der anderen Annotation wurde diese Stelle für keinen Fehler gehalten.
Nachdem wir mithilfe des Reports zum Klassenrauschen einen Überblick über die Inkonsistenz in den Annotationen erhalten haben, gehen wir erneut durch die aufgenommen Defektbilder und vereinheitlichen die Fehlermarkierungen der Praktikant:innen. Anschließend trainieren wir das Modell erneut. Die Erkennungsgenauigkeit des Modells ist nun mit 98% deutlich besser.
Alexander erklärt mir, dass dieses Problem der inkohärenten Annotationen auch häufig bei Kunden auftritt: “Wenn verschiedene Mitarbeitende aus der Qualitätsprüfung die Fehler in den Daten annotieren, kommt es häufig vor, dass die Annotationen, genau wie in unserem Experiment, sehr unterschiedlich ausfallen. Viele unserer Kunden überrascht das, weil sie bisher davon ausgegangen sind, dass die Fehlerdefinition von den Mitarbeitenden einheitlich verstanden wird.” Wenn man etwas darüber nachdenkt, erscheint dieses Abweichen jedoch sehr logisch. Menschen sind individuell und legen Dinge unterschiedlich aus. Selbst wenn ich für die Mitarbeitenden genau festlege, was als Fehler gilt und was nicht, kann es unterschiedliche Auslegungen dieser Fehlerdefinition geben. Gleichzeitig können Menschen mal aufmerksamer und mal weniger aufmerksam sein. Die Konsequenz dieser unterschiedlichen Fehlerdefinitionen und auch der Aufmerksamkeitszustände der Prüfenden ist natürlich, dass die manuelle Qualitätskontrolle inkonsistent ist. Es wird je nach Prüfer:in unterschiedlicher Ausschuss produziert und es werden unterschiedliche Produkte in den Handel gegeben.
Dieser Inkonsistenz manueller Prüfungen wirkt Maddox AI durch das KI-basierte Prüfsystem entgegen. Auch hier können unterschiedliche Fehlerdefinitionen, wie im Experiment gezeigt, beim Annotieren auftauchen. Mithilfe des im Experiment beschriebenen Tools, können Kunden die Diskrepanzen in ihren Daten entdecken. Das macht es auf einem einfachen und schnellen Weg möglich, eine konsistente und sauber annotierte Datenbasis für das Trainieren eines KI-Modells zu erzeugen, was die Performanz des Modells deutlich steigert.
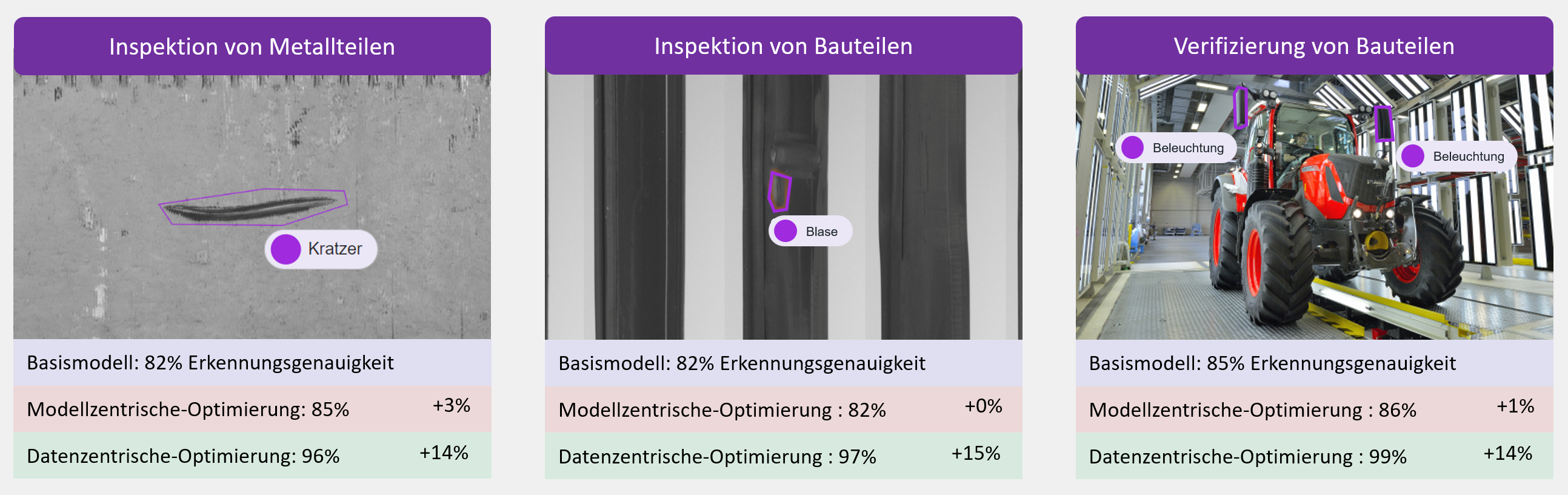
Diese gesteigerte Leistung zeigt sich auch in den Ergebnissen unseres White Papers. Hier haben wir unter anderem verglichen, inwiefern sich modellzentrische Optimierungen und datenzentrische Optimierung auf die Leistung der Modelle auswirken. Es zeigte sich, dass modellzentrische Optimierungen kaum Auswirkungen hatten, während die datenzentrierten Optimierungen eine signifikante Steigerung der Performanz bewirkte.
Wenn auch Sie von dem datenzentrierten Ansatz von Maddox AI und einer konsistent arbeitenden Qualitätskontrolllösung profitieren wollen, melden Sie sich gerne bei uns. Unser Expertenteam berät Sie gerne zu den verschiedenen Möglichkeiten, die Ihnen das Maddox AI-System bietet.
Nachdem ich nun die wichtigsten Grundlagen zum Verständnis von KI-basierter visueller Qualitätskontrolle gelegt habe, wende ich mich in der nächsten Folge im Gespräch mit Peter Droege, Mitgründer und CEO von Maddox AI, den größten Problemen der visuellen Qualitätskontrolle heutzutage zu.
Die größten Probleme in der visuellen Qualitätskontrolle heute
Folge 5
