How can I improve the performance of my AI model?
Episode 4
Author: Hanna Nennewitz
How can I improve the performance of my AI model?
Episode 4
Author: Hanna Nennewitz

I've spent a lot of time on the algorithm side of AI in recent episodes. However, the algorithm is only one of two levers to develop high-performance AI models. Ultimately, I need a combination of the best algorithms and a good database to achieve optimal model performance. I'm going to take a closer look at the topic of data quality today. To do so, I'm going to do a little experiment and talk to Alexander Böttcher about the importance of good data for an AI model to work successfully. At Maddox AI, Alexander Böttcher is an ML engineer responsible for developing the Maddox AI ML training and deployment pipeline. Additionally, he develops ML methods that allow users to quickly annotate consistent datasets.
I’ve spent a lot of time on the algorithm side of AI in recent episodes. However, the algorithm is only one of two levers to develop high-performance AI models. Ultimately, I need a combination of the best algorithms and a good database to achieve optimal model performance. I’m going to take a closer look at the topic of data quality today. To do so, I’m going to do a little experiment and talk to Alexander Böttcher about the importance of good data for an AI model to work successfully. At Maddox AI, Alexander Böttcher is an ML engineer responsible for developing the Maddox AI ML training and deployment pipeline. Additionally, he develops ML methods that allow users to quickly annotate consistent datasets.
Alexander starts our conversation with a little thought experiment: the optimal conditions for a good coffee are obtained on the one hand by a good coffee machine and on the other hand by good coffee beans. Ultimately, however, the taste of the coffee depends mainly on the quality of the beans. If you put bad beans in a perfect coffee machine, you will drink bad coffee, no matter how sophisticated the process of making coffee in the machine may be. Alexander explains to me that it is similar with AI models: “Even with AI models, the prerequisite for a perfectly functioning model is an optimal algorithm and database. However, if I put inconsistent data into an optimal algorithm, that algorithm will still not produce optimal results. For this reason, it’s important to look more closely at the quality of the data you’re using to train an AI.”
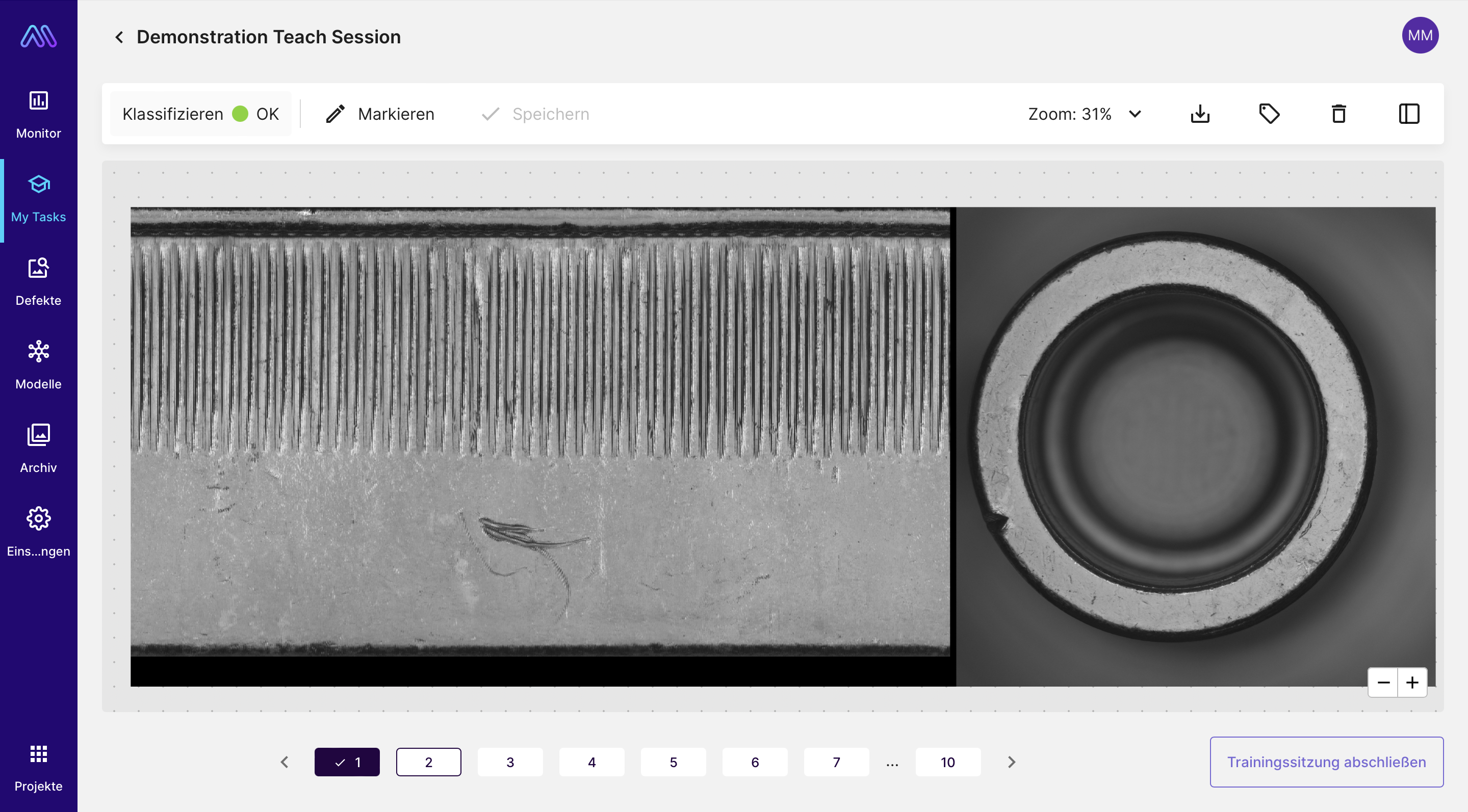
Example image of the parts that were annotated
On these turned parts, they mark defects through polygons and document whether they are scratches or dents. After the annotations are done, we train the Maddox AI system with them. Once the training is complete, we look at the recognition accuracy of the model. It is 74%, which of course is not very good. For me, this immediately raises the question: What is the reason for this? The Maddox AI system usually works very reliably.
Alexander explains to me that it’s due to the quality of the annotated data: “It’s a problem if the data basis with which we train the AI is not consistent, because then the AI doesn’t have consistent data to learn from.”
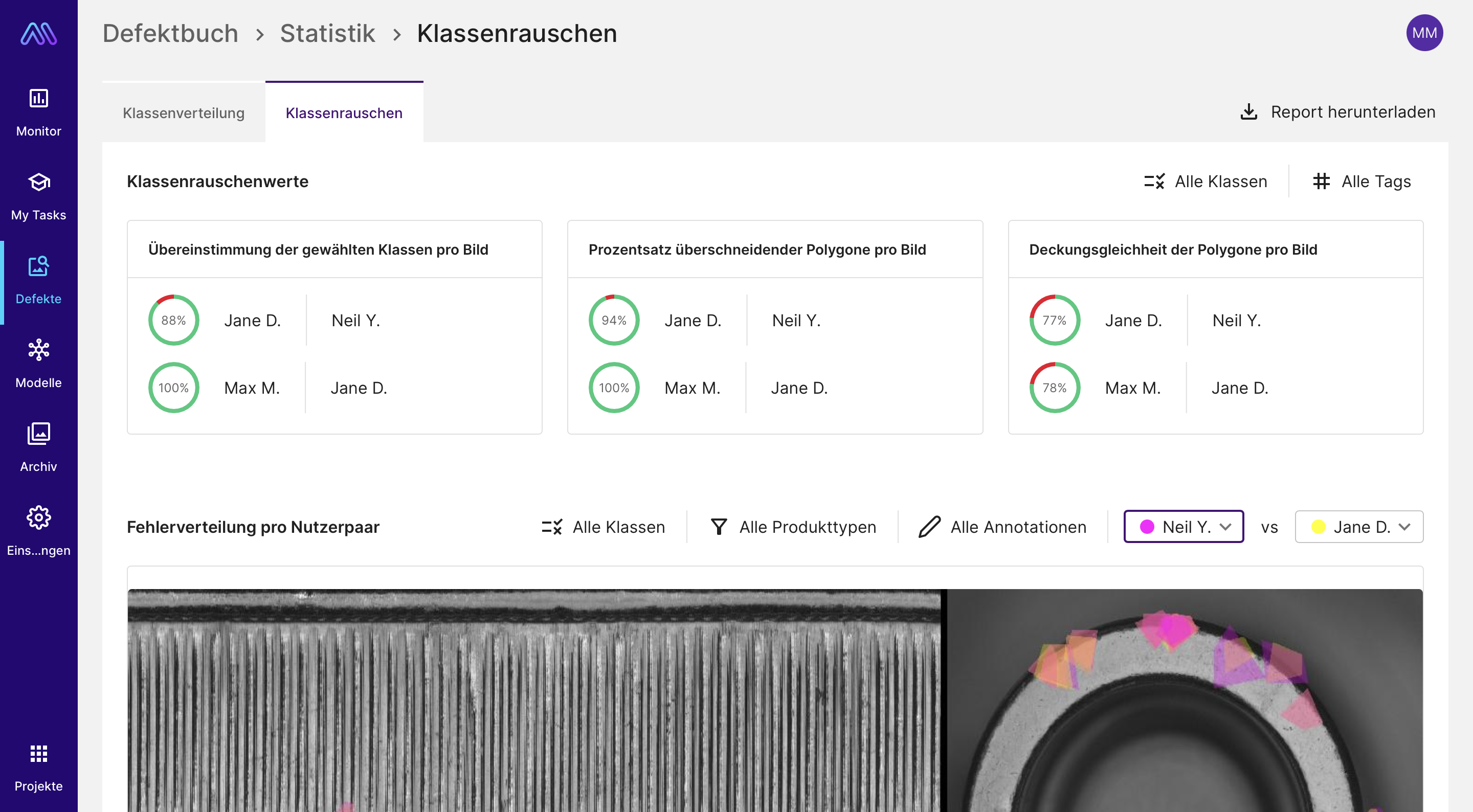
The statistics on label noise in the Maddox AI cloud software, here you can find a rough overview on the consensus between the annotations of the individual annotators.

Example 1: Here, the first person marked two dents, while the other person overlooked the second slightly smaller dent.

Example 2: Here the scratch has been marked very differently. One annotation is very close to the scratch, while the other is drawn very widely and includes many free areas that do not actually belong to the scratch.

Example 3: Here, a scratch was marked. In the other annotation, this spot was not considered an error.
After using the label noise report to get an overview of the inconsistency in the annotations, we go through the recorded defect images again and unify the polygons of the interns. We then train the model again. The recognition accuracy of the model is now much better at 98%.
Alexander explains to me that this problem of incoherent annotations also occurs frequently with customers: “When different employees from quality control annotate the defects in the data, it often happens that the annotations turn out very differently, just like in our experiment. Many of our customers are surprised by this because they have previously assumed that the definition of errors is uniformly understood by the employees.” When you think about it a bit, however, this divergence seems very logical. People are individual and interpret things differently. Even if I define for employees exactly what counts as an error and what does not, there may be different interpretations of this error definition. At the same time, people can sometimes be more attentive and sometimes less attentive. The consequence of these different defect definitions and also the attention states of the inspectors is of course that the manual quality control is inconsistent. Depending on the inspector different rejects are produced and different products are put on the market.
If you too would like to benefit from Maddox AI’s data-centric approach and a quality control solution that works consistently, feel free to contact us. Our team of experts will be happy to advise you on the various possibilities offered by the Maddox AI system.
Now that I’ve laid the key groundwork for understanding AI-based visual quality control, in the next episode I turn to the biggest problem facing visual quality control today in conversation with Peter Droege, co-founder and CEO of Maddox AI.

If you too would like to benefit from Maddox AI’s data-centric approach and a quality control solution that works consistently, feel free to contact us. Our team of experts will be happy to advise you on the various possibilities offered by the Maddox AI system.
Now that I’ve laid the key groundwork for understanding AI-based visual quality control, in the next episode I turn to the biggest problem facing visual quality control today in conversation with Peter Droege, co-founder and CEO of Maddox AI.
The Biggest Problems in Visual Quality Control Today
Episode 5
